지금까지 본 feed forward 신경망은 시계열 데이터를 잘 다루지 못해서 순환 신경망 RNN이 등장해씀

오른쪽처럼 연결하면 단어의 순서도 고려할 수 있지만 그러면 맥락 크기에 비해 가중치 매개변수도 많이 늘어나서 안좋음 ㅠ > RNN 등장햇습니다
RNN
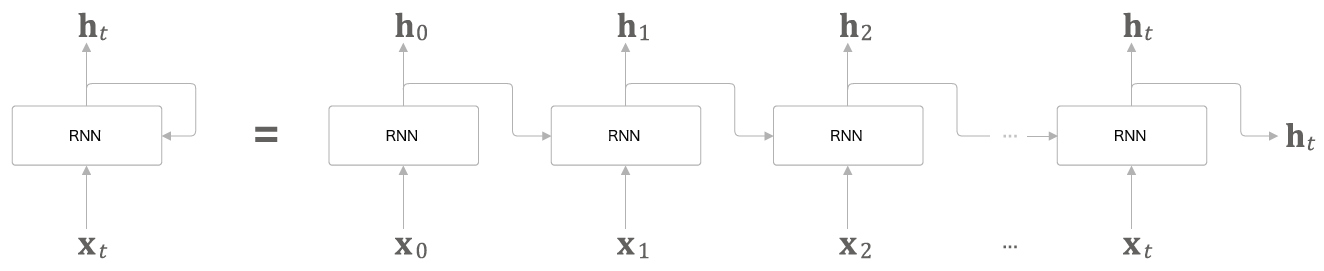
t는 시각. 시계열 데이터 X_t를 입력 받고 h_t 출력

이 식처럼 h_t를 계산하면 위쪽으로 출력되고 동시에 다음 t의 RNN 쪽으로도 출력된다. 현재의 출력값은 이전 t에 기초해 계산되기 때문에 메모리가 있는 계층이라고도 한다! 아니면 은닉 상태 / 은닉 상태 벡터라고도 한다잉
BPTT
RNN계층에서 backprop 하는걸 through time 붙여서 BPTT라고 한다. 그치만 그냥 이걸로 학습하면 긴 시계열 데이터에서 계산량이 너무 많아지고 기울기가 불안정해져서 새로운걸 또 냈다.
Truncated BPTT
이름에서 알수 있듯이 잘린 BPTT. 큰 시계열 데이터를 학습할 때는 신경망 연결을 적당한 길이에서 끊는다. 적당히 잘 끊어서 작은 신경망 여러개로 만드는게 Truncated BPTT.

무작정 끊는다고 좋은 게 아니라 역전파에서의 연결만 끊어야 한다. 순전파는 그대로 순서대로 진행하고 역전파에서만 끊어서 끊어진 순서대로 그 단위별로 학습해야 한다.

암튼 젤 중요한 건 데이터를 순서대로 줘야 하고 미니배치로 학습시키려면 데이터를 시작위치로 옮겨야 한다.

RNNLM
RNN언어모델이라서 LM 붙음. 언어모델은 단어에 확률 부여하는 거

perplexity
언어 모델의 예측 성능을 평가하는 척도, 확률의 역수

모델 1에서는 say가 0.8확률로 다음에 출연한다고 예측했고 이때 perplexity는 1/0.8 = 1.25
perplexity가 1.25라는 의미는 다음에 출현할 수 있는 단어의 후보를 1.25개로 좁혔다는 의미이고 이 값은 작을수록 좋음!
input 단어가 여러개일 때는 아래 공식처럼 계산하면 됨~

t_nk : n개째 데이터의 k번째 값
t_n : 원핫 벡터로 나타낸 정답 레이블
y_nk : 확률분포

끝!

'NLP > 밑바닥부터 시작하는 딥러닝2' 카테고리의 다른 글
| 4장 word2vec 속도 개선 (0) | 2021.04.13 |
|---|---|
| 3장 word2vec (0) | 2021.04.12 |
| 2장 자연어&단어 분산 표현 (0) | 2021.02.22 |
| 1장 신경망 복습 (0) | 2021.02.21 |