시소러스
유의어 사전. 동의어나 유의어가 한 그룹으로 분리되어 있음

단어의 상하위 / 전체or부분 으로 더 자세하게 구분할 수도 있음. 그러면 위 사진처럼 그래프 모양으로 정의.
이런 단어 네트워크를 이용해서 컴퓨터한테 단어 사이의 관계를 가르칠 수 있음.
단점 ...
- 사람이 직접 하나하나 해서 귀찮고 시간도 많이 필요함. 비용 ㄷㄷ
- 시대 변화에 대응하기 어려움. 안 쓰는 말이 될 수도 있고 새로운 말이 생길 수도 있음.
- 빈티지 / 레트로 사이의 미묘한 차이 같은 걸 정의할 수 없음
통계 기반 기법
말뭉치 nlp연구 같은걸 생각해두고 수집된 대량의 텍스트 데이터
어쨌든 말뭉치는 사람들이 쓴 문장을 수집한 거라 문법, 단어 선택, 의미 같은 지식이 담겨있다고 볼 수 있음.
통계 기반 기법은 말뭉치를 쓰면서 사람 지식을 훔쳐다 쓰는거나 마찬가지
분산 표현 단어를 벡터로 표현 > 단어의 의미를 정확하게 파악할 수 있음
분포 가설 단어의 의미는 주변 단어에 의해 형성된다. > 맥락이 의미를 형성함
맥락! 특정 단어를 중심으로 그 단어 주변의 단어. 윈도우 크기에 따라 주변 단어 몇개까지 쓸지 결정
동시발생 행렬 co-occurence matrix
'You say goodbye and I say hello.' 라는 문장에서 윈도우 1일때 다른 단어들의 빈도 표
그냥 행렬처럼 생겨서 동시발생 행렬인듯

벡터 간 유사도

cosine similarity는 두 벡터가 가리키는 방향이 얼마나 비슷한지 볼수 있음.
벡터 두개 방향이 완전히 똑같으면 1, 정반대면 -1
점별 상호정보량 pointwise mutual information(PMI)
PMI 값이 높을수록 관련성이 높다는 의미.
두 단어가 붙어서 나온다고 무작정 유사도가 높다고 판단하지 않고 단어가 단독으로 출현하는 횟수도 고려해서 cosine similarity보다 개선됐지만, 두 단어가 겹치는 일이 한번도 없으면 값이 -무한대 돼서 다른거 씀

C 동시발생 행렬
C(x, y) x랑 y가 동시에 나오는 횟수
C(x) x 나오는 횟수
N 말뭉치에 있는 총 단어 수
양의 상호정보량 Positive PMI
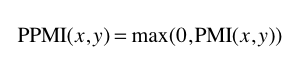
PMI가 음수일 때는 0으로 취급. > 단어 사이 관련성을 0 이상의 실수로 나타낼 수 있음
차원 감소
PPMI는 단어 개수에 따라서 행렬 차원이 늘어나고, 서로 별로 안중요한 애들이 많아서 차원 축소를 함
singular value decomposition(SVD) 특이값 분해
임의의 행렬을 세 행렬의 곱으로 분해. 이거 쓰면 밀집벡터로 바꿀 수 있음

U, V는 orthogonal이고 S는 diagonal임.



말뭉치 귀여운듯 말뭉치 솜뭉치 털뭉치
'NLP > 밑바닥부터 시작하는 딥러닝2' 카테고리의 다른 글
| 5장 RNN (0) | 2021.04.16 |
|---|---|
| 4장 word2vec 속도 개선 (0) | 2021.04.13 |
| 3장 word2vec (0) | 2021.04.12 |
| 1장 신경망 복습 (0) | 2021.02.21 |