Abstract
- 모델 확장을 체계적으로 연구, 기준 네트워크를 설계한 후 확장
- 네트워크 깊이, 폭, 해상도의 모든 차원을 균일하게 확장하는 새로운 방법 제안
- ImageNet에서 84.3% 정확도, 기존 최고성능 ConvNet보다 8.4배 작고 6.1배 빠름
- 훨씬 적은 수의 parameter로 최고 정확도 달성!
1. Introduction
체계적이지 않았던 ConvNet 확장! 우리가 효과적으로 확장하는 방법 알려준다 ㅋ
원래는 depth나 width를 확장하는 경우가 많았고 요새는 이미지의 해상도에 따라 모델을 확장하는 경우가 많아지고 있음. 이 3가지 중 한개만 확장하는 게 일반적이고 수동으로 조정해야되는데다가 확장해도 정확도가 개선되지 않는 경우 有
이 논문에서는 ConvNet을 확장하는 걸 다시 체계적으로 연구한다.
우리가 한 연구에 따르면 네트워크의 너비/깊이/해상도 3가지 차원의 균형을 맞추는 게 중요하고 균형은 일정한 비율로 조정해 맞출 수 있다.
임의로 조정하는 게 아니라 fixed scaling coefficient set으로 위 3개를 균일하게 조정.
예를 들어 2N배 더 많은 계산을 하려면 네트워크 깊이를 αN, 너비를 βN, 이미지 크기를 γN 만큼 늘린다(α, β, γ는 결정 상수 계수). 작은 모델에 대한 grid search는 아래 그림과 같이 기존 scaling 이랑 우리가 한 게 차이를 보임.

MobileNet, ResNet에서 확장 방법이 잘 먹힌다. 모델 확장의 효율은 기준 네트워크에 크게 좌우되기 때문에 우리는 새로운 기준 네트워크를 만들고 이걸 확장해서 EfficientNet이라는 모델을 만든다. EfficientNet은 파라미터 수가 더 적고 계산이 훨씬 빠른 데다가 높은 성능을 보여준다!
2. Related Work
[ConvNet Accuracy] AlexNet 이후로 ConvNet은 더 커지면 더 정확해졌음. 그러나!!! 이미 너무 커져서 메모리가 한계에 도달했기 때문에 더 높은 정확도를 위해선 더 나은 효율성이 필요하게 됐다.
[ConvNet Efficiency] Deep ConvNet은 자주 over-parameterized된다. 압축은 효율을 위해 모델 크기를 줄이는 일반적인 방법, MobileNet처럼 효율적인 모바일용 ConvNet을 만드는 방법이 최근 대중화되고 있고 엄청나게 크게 만든 모바일 ConvNet보다 훨씬 더 높은 효율을 보여줌. 작은 모델에선 이런 연구가 잘 되고 있지만 대형 모델에서는 어떻게 해야할 지 불문명하기 때문에 우리가 연구한다. 초대형 ConvNet의 모델 효율성을 모델 확장에 의존해 연구한다.
[Model Scaling] ConvNet을 확장하기 위해 ResNet은 layer(깊이)를 조정했고, WideResNet과 MobileNet은 channel(너비)을 조정했다. 이전 연구에 따르면 깊이와 너비가 모두 ConvNet에 중요하지만 더 나은 효율성, 정확성을 위해 어떻게 효과적으로 ConvNet을 확장할 지는 잘 모름! 우리가 width, depth, resolution 세가지 차원으로 ConvNet Scaling을 체계적으로 연구한다.
3. Compound Model Scaling
3.1. Problem Formulation
ConvNet Layer i는 Yi라는 함수로 정의할 수 있다.
ConvNet N은 구성된 layer 목록으로 나타낼 수 있고 아래 그림처럼 식으로 나타낼 수 있다.
ConvNet layer는 여러 stage로 분할되고 각 단계의 모든 레이어는 동일한 architecture를 공유한다. 예를 들어 ResNet은 5개의 단계가 있고 각 단계의 레이어는 down-sampling을 수행하는 첫번째 레이어를 제외하고 모두 같은 convolutional type을 가진다. 따라서 아래 식1과 같이 ConvNet을 정의할 수 있다.
Figure 2 (a) 는 공간 차원이 점점 축소되지만 채널 차원은 확장되는 걸 보여준다.
예를 들어 초기 input shape (224, 224, 3)에서 최종 output shape (7, 7, 512)
보통 ConvNet이 최고의 layer architecture F_i를 찾는 데 집중하는 것과 달리 model scaling은 기준 네트워크에 미리 정의된 F_i를 바꾸지 않고 길이(L_i), 너비(C_i), 해상도(H_i, W_i)를 확장하려고 한다. F_i를 고정함으로써 model scaling은 새로운 리소스 제약에 대한 설계 문제를 단순화하지만, 아직도 각 레이어의 큰 design space에서는 다른 L_i, C_i, H_i, W_i에 대한
design space를 더 줄이기 위해 우리는 모든 layer가 일정한 비율로 똑같이 scaled되게 제한했다. 우리의 목표는 주어진 제약조건에서 모델 정확도를 최대화하는 것! 우리는 그걸 optimization problem으로 공식화할 수 있다.
w, d, r은 네트워크의 width, depth, resolution을 스케일링하기 위한 계수
F^_i, L^_i, H^_i, W^_i, C^_i 은 표1에서 보는거처럼 기준 네트워크에서 미리 정의된 파라미터들
3.2. Scaling Dimensions
문제2의 가장 큰 어려움은 최적의 d, w, r이 서로 의존하고 각 값이 서로 다른 리소스 제약 조건에서 변경된다는 것이다. 그래서 기존 방법들은 대부분 Depth, Width, Resolution 중 하나의 차원으로 ConvNet을 확장한다.
Width(w) 네트워크의 width 확장은 보통 작은 크기의 모델에 적용한다. 넓은 네트워크는 더 많은 feature를 찾아낼 수 있지만 넓기만 하고 깊이가 얕으면 feature를 찾아내는 데 별로 좋진 않다. Figure3의 왼쪽에 있는 게 그 예시인데 w가 커진다고 무조건 정확도가 높아지진 않는 걸 보여준다.
Depth(d) 깊이 확장은 많은 ConvNet에서 사용되는 가장 일반적인 방법. 더 깊은 ConvNet은 더 많고 복잡한 feature를 캡처하고 잘 일반화 할 수 있지만, 깊은 네트워크는 기울기 소실 문제 때문에 훈련하기 더 어렵다. skip connection이나 batch normalization 같은 여러가지 기술이 문제를 완화하지만 아주 깊은 네트워크의 정확도는 감소한다. Figure3의 가운데 있는 애는 baseline model에서 d를 스케일링 한 결과인데 깊은 네트워크에서 정확도가 감소하는 걸 보여준다.
Resolution(r) 해상도가 높은 이미지를 사용하면 ConvNet이 더 세밀한 패턴을 찾아낼 수도 있다. 점점 높은 해상도의 이미지를 사용하는 경향이 있고, 최근의 GPipe는 480x480 해상도로 최고 정확도를 달성했다. Figure3의 오른쪽 그림이 r을 높인 경우인데 실제로 해상도가 높을수록 정확도가 향상되지만 정확도가 올라갈수록 그 폭이 감소한다.
[Observation 1] width, depth, resolution 중 어떤 차원을 확장해도 정확도가 올라가지만 더 큰 모델의 경우엔 감소한다.
3.3. Compound Scaling
3.1.에서 본 것처럼 각 스케일링 차원들이 독립적이지 않다는 것을 알 수 있다. 높은 해상도의 이미지를 사용하면 네트워크의 너비도 늘려야되고 너비만 늘어나면 안되니까 깊이도 늘려야된다. 실제로 맞는 말인지 검증하기 위해 d와 r이 1일 때 w만 스케일링해보고(파란색), d와 r이 더 클 때 w만 스케일링해본다(빨간색).
한눈에 봐도 파란색보다 빨간색이 더 정확도가 높은 걸 알 수 있다. 따라서 w, d, r 중에 한가지만 스케일링한다고 좋은 게 아니라 다같이 균형을 맞춰서 스케일링해야 된다!
[Obervation 2] 더 높은 acc와 효율을 위해 ConvNet을 확장하려면 w, d, r 모든 차원의 균형을 맞추는 게 중요하다.
따라서 우리는 새로운 compound scaling method를 제안한다!
네트워크의 w, d, r을 균일하게 조정하기 위해 복합 계수인 φ를 사용!
여기서 α, β, γ는 small grid search에 의해 결정되는 상수, φ는 모델 스케일링을 위해 사용할 수 있는 resource 수를 제어하는 user-specified 계수이고 α, β, γ는 추가 resource를 네트워크의 w, d, r에 구체적으로 배정하는 역할을 한다.
보통 convolution의 FLOPS는 d, w^2, r^2에 비례하고 d를 2배로 늘리면 2배, w나 r을 2배로 늘리면 4배 증가한다. convolution 연산이 ConvNet의 계산을 대부분 차지하기 때문에 ConvNet을 식3으로 확장하면 대략 전체 FLOPS가 (α · β · γ)^φ으로 늘어난다.
이 논문에서는 새로운 φ에 대해 총 FLOPS가 2^φ만큼 증가하도록 α · β^2 · γ^2 ≈2로 제한한다.
4. Efficient Architecture
기존 ConvNet을 사용해 확장 방법을 평가하긴 할 건데 효과를 더 잘 보여주고 싶어서 EfficientNet이라는 새로운 모바일 크기 기준 네트워크를 개발했다.
acc, FLOP 모두를 최적화하는 다목적 nueral architecture search를 통해 기준 네트워크(EfficientNet-B0이라는 MnasNet과 비슷하지만 좀 더 큰! 효율적인 네트워크)를 개발한다. 좀 더 구체적으로, 아래 식과 같은 search space를 최적화의 목표로 정한다.
ACC(m)과 FLOPS(m)은 모델 m의 정확도와 FLOPS, T는 타겟 FLOPS
w = -0.07 는 acc와 FLOPS 사이의 trade-off 관계를 제어하는 하이퍼파라미터
이렇게 만든 EfficientNet-B0에 우리의 복합 스케일링 방법을 적용해 2단계를 거쳐 확장한다.
[1단계] φ = 1 을 고정해두고, 사용할 수 있는 리소스가 2배 많다고 가정. α, β, γ에 대해 식2, 식3에 기반한 small grid search를 수행한다. EfficientNet-B0에 대한 best value는 α · β^2 · γ^2 ≈ 2라는 가정 하에 아래와 같음
α = 1.2, β = 1.1, γ = 1.15
[2단계] 앞서 구한 α, β, γ를 고정해두고, EfficientNet-B1 ~ B7을 얻기 위해 φ를 다 다른 값으로 식3에 적용해 기준 네트워크를 확장한다.
α, β, γ는 큰 모델에서 search하면 좋은 성능을 얻을 수 있지만 search cost가 넘 비싸! 그래서 우리는 작은 기준 네트워크에서 α, β, γ를 딱 한번만 search한 다음 다른 모든 모델에 동일한 값을 사용해서 스케일링했다.
5. Experiments
5.1. Scaling Up MobileNets and ResNets
많이 사용되는 MobileNet과 ResNet에 우리가 만든 확장 방법 적용. 다양한 방식으로 확장한 모델들의 ImageNet결과가 위 표에 있음 ! 우리의 compound scaling 방법은 모든 모델의 정확도를 향상시키는 것을 알 수 있음
5.2. ImageNet Results for EfficientNet
EfficientNet-B0에서 0.2 EfficientNet-B7에서 0.5로 drop out 비율을 선형적으로 증가시킨다.
train set 에서 랜덤으로 선택한 25K 이미지를 minival set으로 쓰고 minival에서 early stoppng.
최종적으로 early stopeed checkpoint에서 origin val set으로 정확도 평가.
베이스라인인 B0부터 확장된 모델 7개의 성능 측정. EfficientNet은 일반적으로 다른 ConvNet보다 훨씬 적은 수의 파라미터와 FLOPS을 사용한다. 특히 B7은 66M개 파라미터와 37B FLOPS로 젤 높은 정확도를 찍었고 이전에 최고였던 GPipe보다 8.4배 작음. EfficientNet을 위해 커스터마이징 된 더 나은 architecture, scaling, training settin에서 비롯된 결과다.
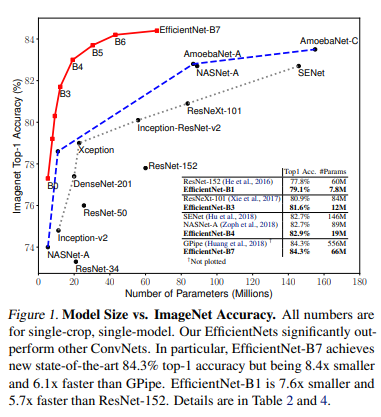
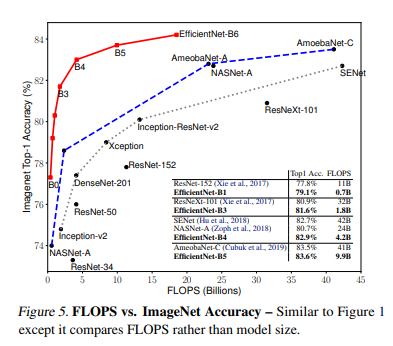
확장된 EfficientNet이 다른 모델들보다 적은 파라미터, 적은 FLOPS를 써서 모델이 작은데다가 계산 비용도 싸게 먹힌다.
latency를 검증하려고 몇개 ConvNet을 꼽아서 CPU에서 inference latency 측정. 20회 실행에 대한 평균 latency인데 B1은 ResNet-152보다 5.7배 빠르고 B7은 GPipe보다 6.1배 빠르다. 실제로 빠른거 검증!
5.3. Transfer Learning Results for EfficientNet
일반적으로 사용되는 dataset에서 EfficientNet 평가.
(1) NASNet-A와 Inception-v4와 비교해서 평균 4.7배(최대 21배) 파라미터 감소, 정확도 ↑
(2) DAT와 GPipe와 비교해서 8개 dataset 중 5개 set에서 9.6배 적은 파라미터로 정확도 ↑
EfficientNet이 다른 모델들보다 훨씬 적은 수의 파라미터로 더 높은 정확도를 보여줌.
6. Discussion
같은 EfficientNet-B0에서 시작해서 어떤 방식으로 확장했는지에 따라 그래프 색을 다르게 표현. ImageNet 성능을 비교한 표! 빨간색이 우리 연구 한거 적용한 결과임. 더 좋다 ~
스케일링 방법이 다른 몇가지 모델들에 대한 class activation map을 비교해보자. 맨 오른쪽에 있는 compound scaling을 사용하는 모델이 더 정확하게 object detail을 찾고 관련있는 영역에 focus하지만 다른 애들은 못함 ㅋㅋ
7. Conclusion
이 논문에서는 ConvNet scaling을 체계적으로 연구하고, 모델 효율성을 유지하면서 보다 원칙적인 방식으로 기준 ConvNet을 쉽게 확장할 수 있는 효과적인 compound scaling 방법을 제안했다. 이 방법을 통해 Mobilesize EfficientNet 모델은 훨씬 적은 파라미터와 FLOPS로 최고 정확도를 뛰어 넘고, 효과적으로 확장할 수 있음을 보여줬다.
'CV > 논문' 카테고리의 다른 글
| [ViT] An Image is Worth 16X16 Words: Transformers for Image Recognition at Scale (0) | 2021.05.20 |
|---|---|
| ShuffleNet (0) | 2021.04.08 |
| MobileNets 논문 (0) | 2021.03.25 |